Case Study #1 Follow-up
RanketAI Self-Measurement Case Study — Reaching B
D → B two-tier progression in 43 days + measurement conditions correction (2026-05-01 ~ 2026-06-13)
RanketAI measurement results (evidence)

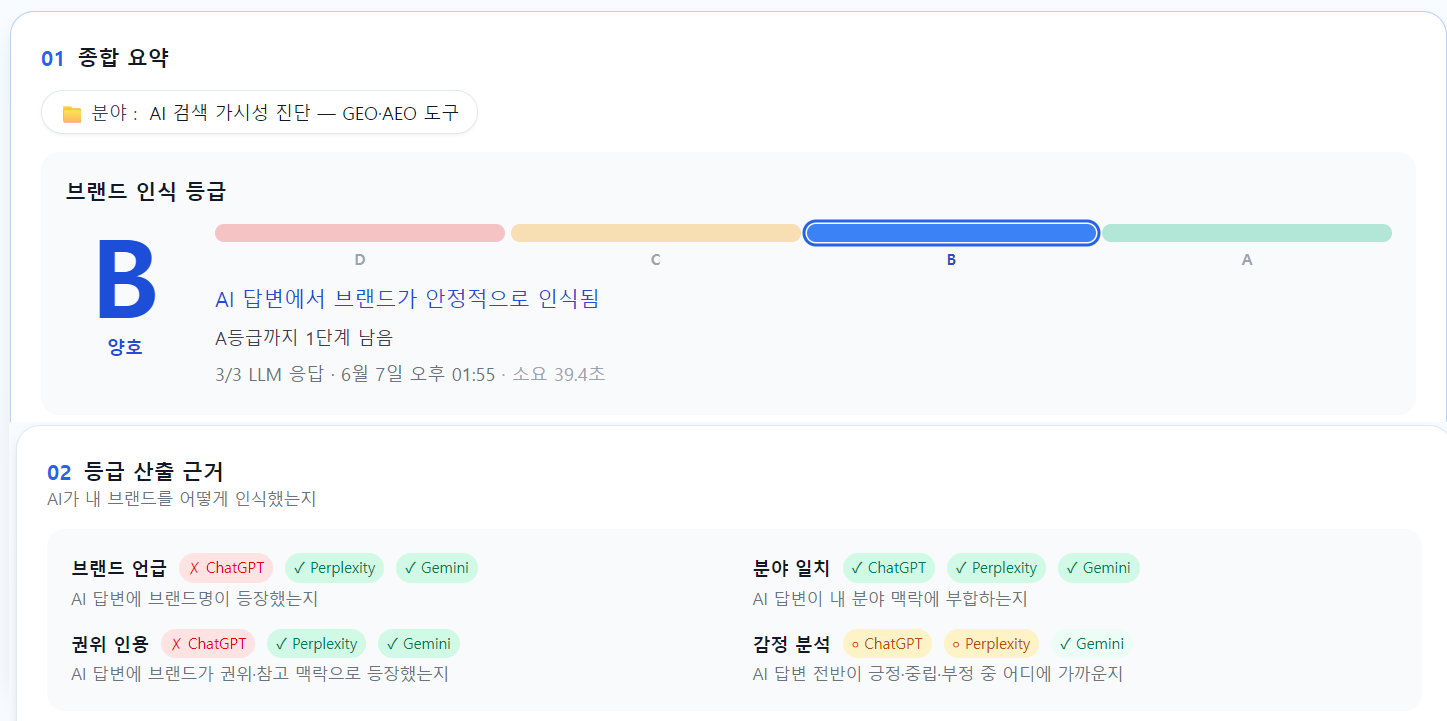
RanketAI measurement — 2026-06-07 (grade · grading basis)
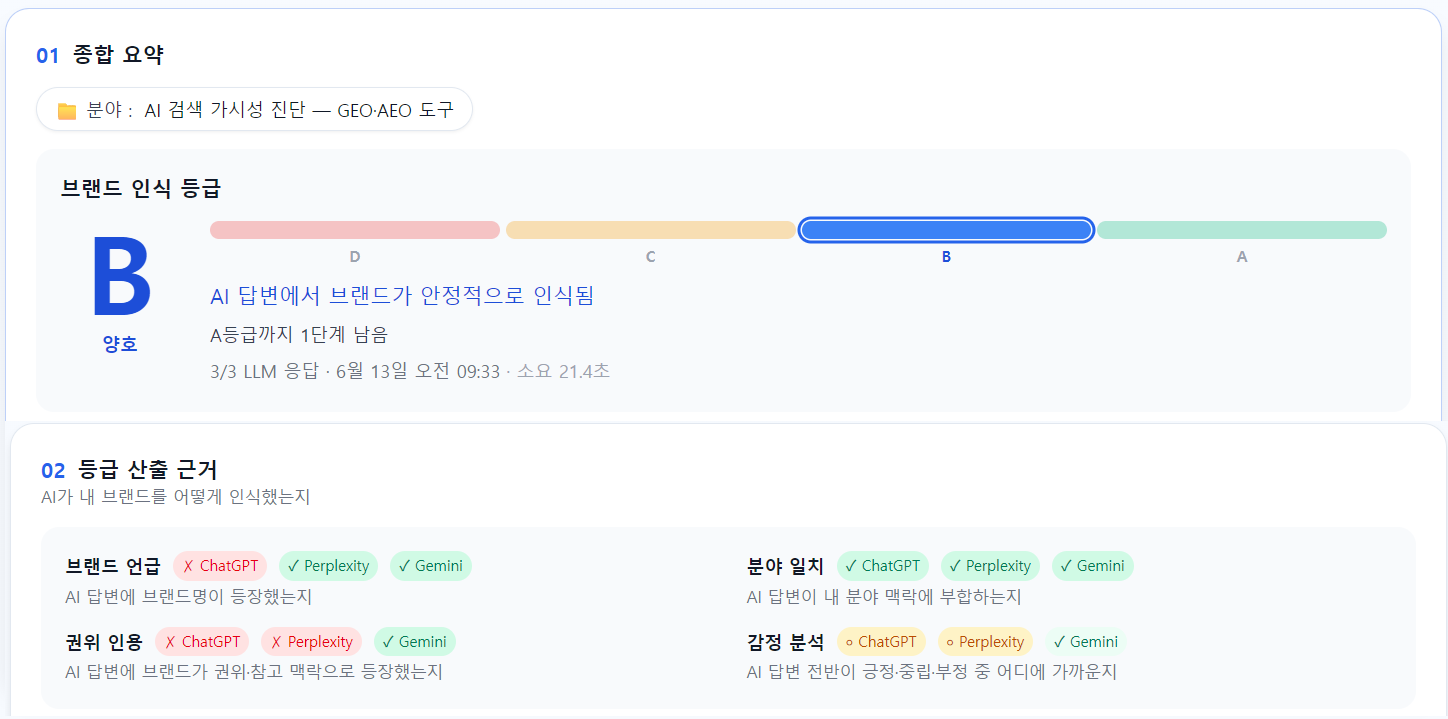
RanketAI measurement — 2026-06-13 (grade · grading basis)
Key takeaways
- • D → B two-tier progression in 43 days without press coverage or ads — own content plus self-serve listings (Crunchbase · GPT Store) only
- • Measurement correction disclosed — the May runs measured ChatGPT and Gemini without web search, structurally blind to a new brand; from June the measurement matches real-user conditions (web search · grounding)
- • Remaining lever = earned citations — ChatGPT non-mention and deep-context queries are the B → A challenges
Measurement conditions correction (v1 → v2)
The 2026-05 issue's measurements (v1) ran two of the three platforms — ChatGPT and Gemini — without web search. A new brand launched after the training cutoff is structurally invisible under that condition, which is why citations appeared only on Perplexity, the platform with built-in search.
From 2026-05-31, ChatGPT web search and Gemini grounding are enabled, aligning the measurement with how real users actually query AI (v2). The same own-media content measures as B under v2, and Gemini citations appear for the first time.
We therefore mark the correction point explicitly so D→C→B is not read as a continuous rise under a single condition. The C→B uplift mixes content/entity improvements with the measurement correction — the two effects are not separately verified.
Timeline
| Date | Grade | Cited responses | Progression note |
|---|---|---|---|
| 2026-05-01 | D | 0 | Baseline (measurement conditions v1) — brand not mentioned in Perplexity answers |
| 2026-05-21 | C | 4 | Brand mentioned in Perplexity answers — 4 citations from a single glossary page (conditions v1) |
| 2026-05-25 | C | 6 | Citations expanded in Perplexity — 3 glossary + 3 blog explainer (conditions v1, last measurement of the 2026-05 issue) |
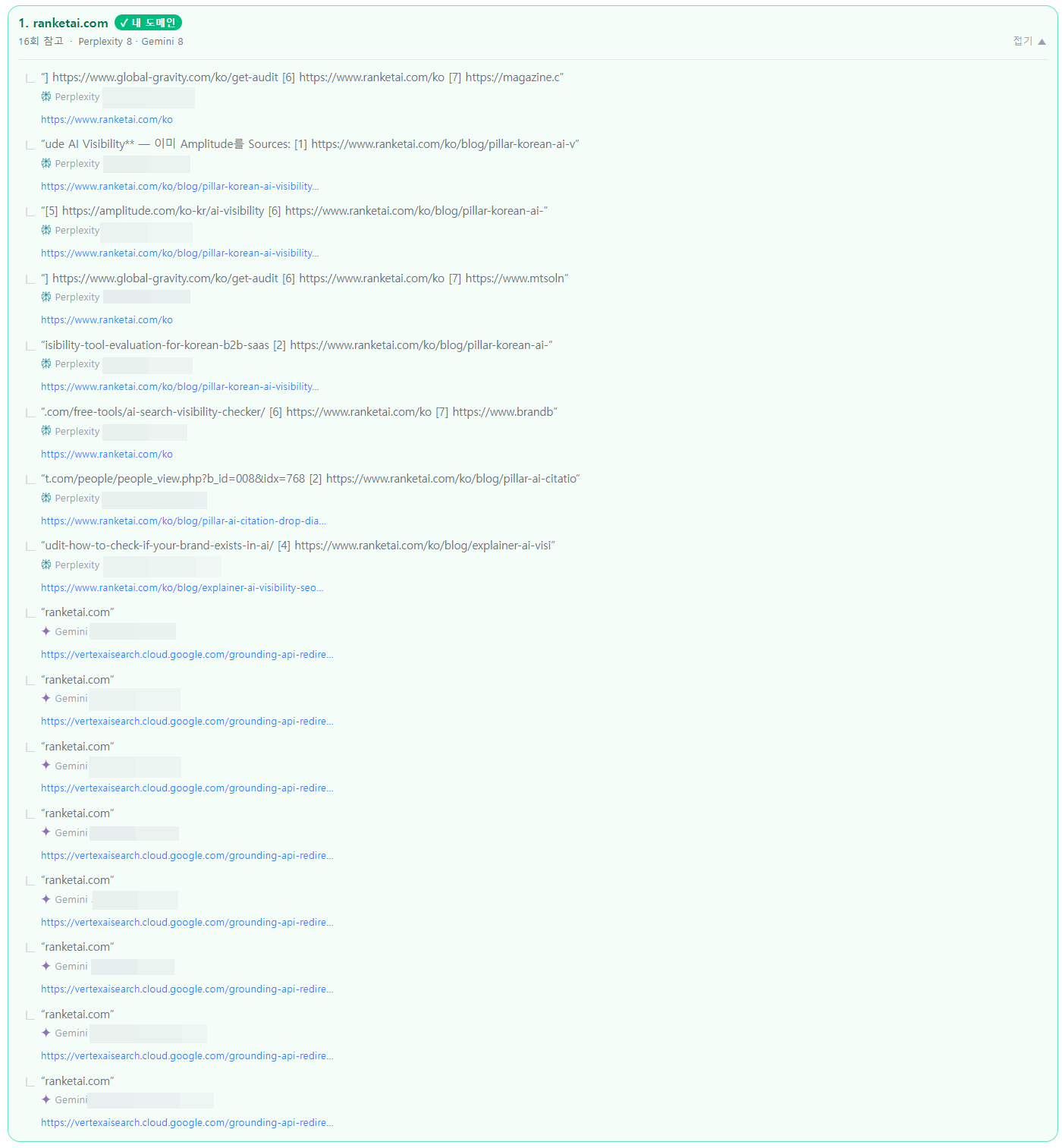
| 2026-06-07 | B | 16 | First measurement under conditions v2 — reached B. Perplexity 8 + Gemini 8 citations (Gemini new). ChatGPT still does not mention the brand even with web search |
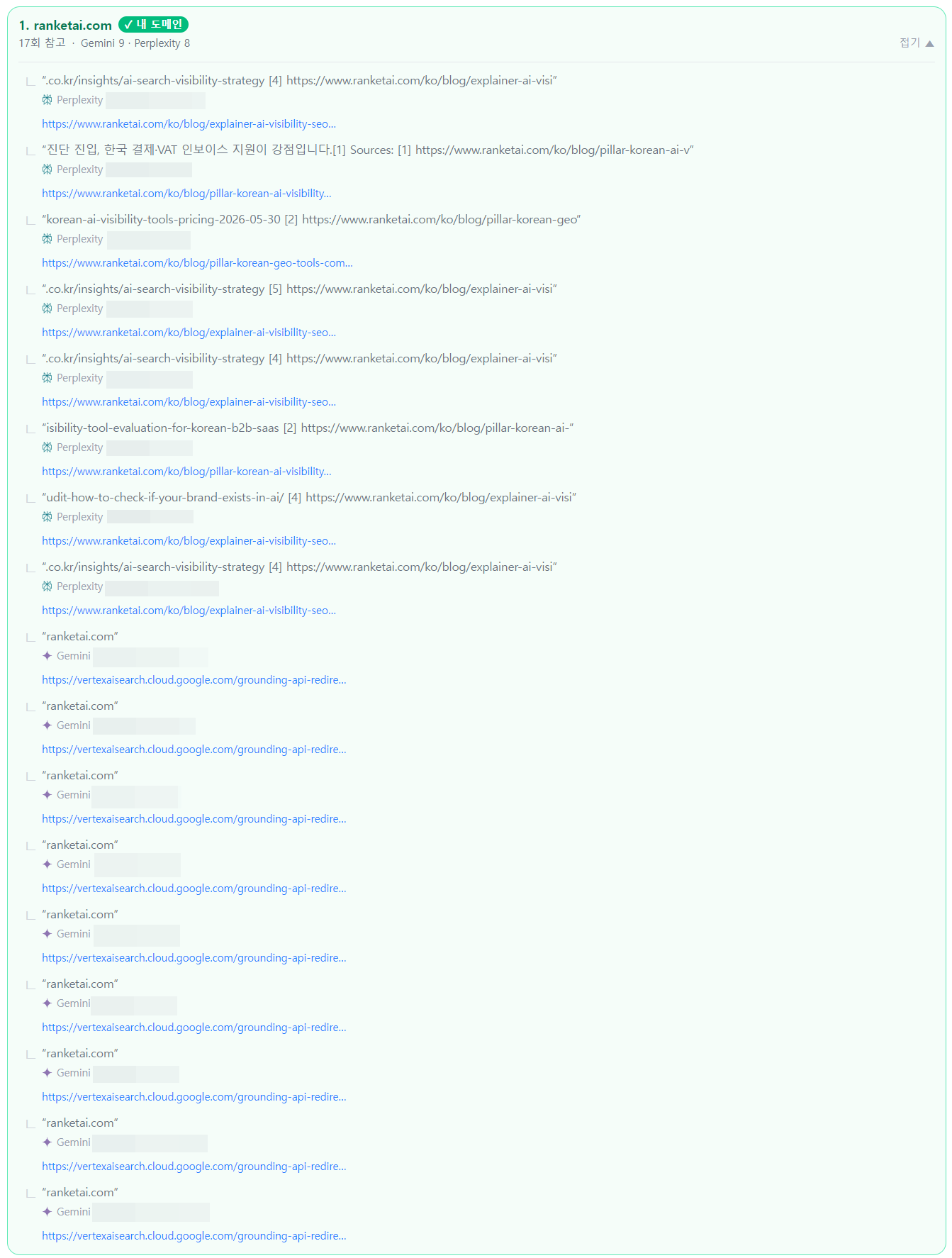
| 2026-06-13 | B | 17 | B sustained (2 consecutive runs) — Perplexity 8 + Gemini 9. Cited assets expanded from glossary to pillar/explainer blog posts |
※ Measurement conditions changed from v1 to v2 between 2026-05-25 and 2026-06-07 (see the correction section above). Do not compare May and June grades on the same scale.
What we applied between C → B
Actions applied after the 5.25 (C) measurement and before the June measurements. Causality with the observed uplift is not guaranteed — it is mixed with the measurement correction effect.
Brand entity structuring
- • Three-layer brand definition (identity · category · feature keywords) — applied consistently to schema entities, page metadata, and JSON-LD
- • The same entity wording synchronized across 40 blog, glossary, and use-case files
Content publishing + direct external listings
- • Five pillar articles published around comparison, pricing, and diagnostics guides (with inline sources and statistics)
- • Crunchbase and GPT Store listings — self-serve registrations, not earned media
Cited own-media pages
Own-media pages cited in AI answers at the latest measurement (2026-06-13).
| Page | Citation count |
|---|---|
| Why Your Content Is Invisible to AI Search: AI Visibility Diagnosis from SEO to GEO and AAO/ko/blog/explainer-ai-visibility-seo-geo-aao-2026-03-14 | 5 |
| Korean AI Visibility Tools Pricing — From Free to Enterprise (2026)/ko/blog/pillar-korean-ai-visibility-tools-pricing-2026-05-30 | 2 |
| Korean GEO Tools Comparison — 5 Categories of AI Visibility Diagnostics (2026)/ko/blog/pillar-korean-geo-tools-comparison-2026-05-30 | 1 |
This table counts only the 8 Perplexity citations from the 2026-06-13 run (page-level identifiable). The 9 Gemini citations resolve through grounding redirects and are only verifiable at the domain level — excluded from the table.
Strengths and remaining gaps
- • Strength — brand/category-centric queries: own pages are cited consistently in Perplexity and Gemini answers (No. 1 cited domain).
- • Gap — ChatGPT: the brand is still not mentioned even with web search. Likely causes: parametric knowledge and the absence of external authority citations.
- • Next frontier = earned citations — the earned-media hypothesis the 2026-05 issue framed as a 'C→B requirement' is revised and carried forward as a B → A lever.
Measurement methodology
This measurement follows these principles.
- • Tool: RanketAI's own measurement tool (dogfooding)
- • LLMs: Major LLMs (ChatGPT · Gemini · Perplexity) — v2: web search/grounding enabled
- • Prompts: Diverse intent-based combinations
- • Grades: 4 tiers (A / B / C / D)
Limits
- • Measured target = 1 domain (RanketAI self) — category sample expansion moved to the 2026-07 issue (adjusted from the original June announcement)
- • Five snapshots are not a trend — LLM answers vary run to run even under identical conditions (signal composition shifted between 6.7 and 6.13). Read grades conservatively.
- • The timeline mixes measurement conditions v1 and v2 — content effects and the measurement correction effect within the C→B uplift are not separately verified.
- • Sentiment analysis is again excluded from this issue (per-measurement variability) — multi-run averaging is under consideration.
- • This report is self-reported — the raw aggregates are published as data.json and data.md to keep it verifiable.