사례 #1 후속 보고서
RanketAI 자체 측정 사례 — D→B 달성
43일 만에 D → B 2단계 진전 + 측정 조건 교정 (2026-05-01 ~ 2026-06-13)
RanketAI 측정 결과 (실증)

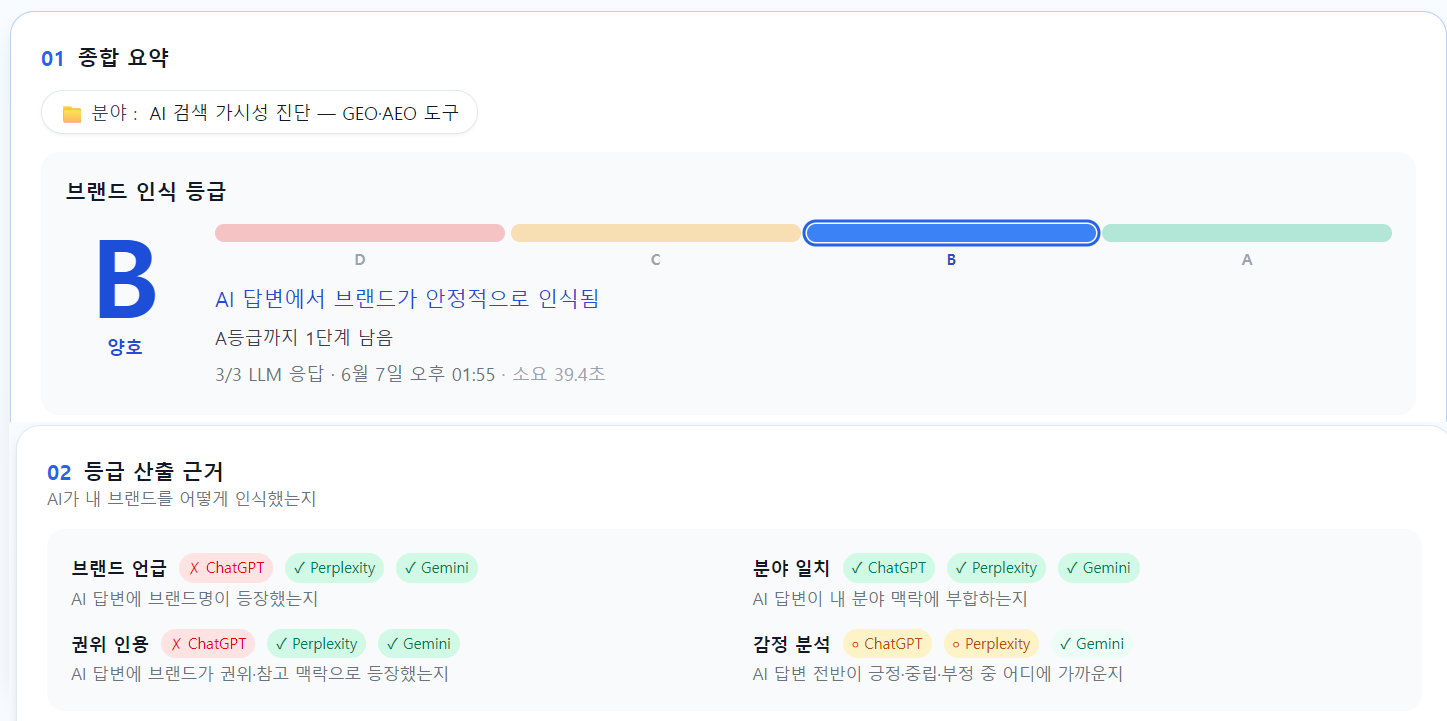
RanketAI 측정 — 2026-06-07 (등급·산출 근거)
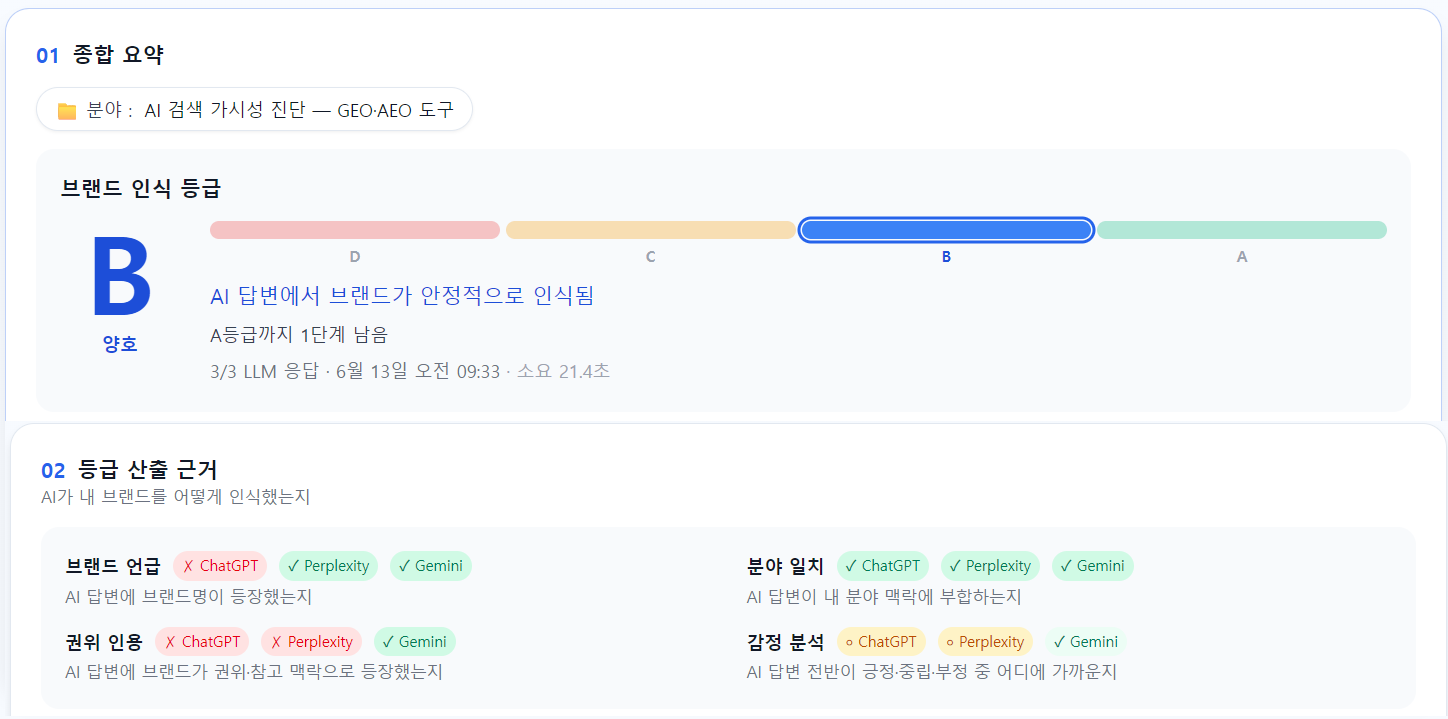
RanketAI 측정 — 2026-06-13 (등급·산출 근거)
핵심 요약
- • 외부 언론 보도·광고 없이 43일 만에 D → B 2등급 상승 — 자사 콘텐츠와 직접 등재(Crunchbase·GPT Store)만 사용
- • 측정 조건 교정 공개 — 5월 측정은 ChatGPT·Gemini가 웹 검색 없이 동작해 신생 브랜드를 구조적으로 보지 못했고, 6월부터 실사용 조건(웹 검색·grounding)으로 교정
- • 남은 레버 = 외부 인용(earned citation) — ChatGPT 미언급과 심층 맥락 질의가 B → A 구간 과제
측정 조건 교정 (v1 → v2)
2026-05 호의 측정(v1)은 세 플랫폼 중 ChatGPT·Gemini 둘이 웹 검색 없이 답하는 조건이었습니다. 학습 컷오프 이후 등장한 신생 브랜드는 이 조건에서 구조적으로 보이지 않으며, 검색이 내장된 Perplexity에서만 인용이 확인된 이유가 여기에 있습니다.
2026-05-31부터 ChatGPT 웹 검색·Gemini grounding을 활성해, 실제 사용자가 AI에게 묻는 조건과 측정을 일치시켰습니다(v2). 같은 자사 콘텐츠가 v2 조건에서 B로 측정되고, Gemini 인용이 새로 잡히기 시작했습니다.
따라서 D→C→B를 단일 조건의 연속 상승으로 읽지 않도록 시계열에 교정 시점을 명시합니다. C→B 상승분에는 콘텐츠·엔티티 개선 효과와 측정 교정 효과가 함께 들어 있으며, 두 효과는 분리 검증되지 않았습니다.
Timeline
| 날짜 | 등급 | 인용 응답 | 진전 근거 |
|---|---|---|---|
| 2026-05-01 | D | 0건 | 시작점 — 측정 baseline (측정 조건 v1). Perplexity 답변에 브랜드 미언급 |
| 2026-05-21 | C | 4건 | Perplexity 답변에서 브랜드 언급 — 용어사전 단일 페이지에서 4건 인용 (측정 조건 v1) |
| 2026-05-25 | C | 6건 | Perplexity 인용 확대 — 용어사전 3건 + 블로그 해설 3건 (측정 조건 v1, 2026-05 호 마지막 측정) |
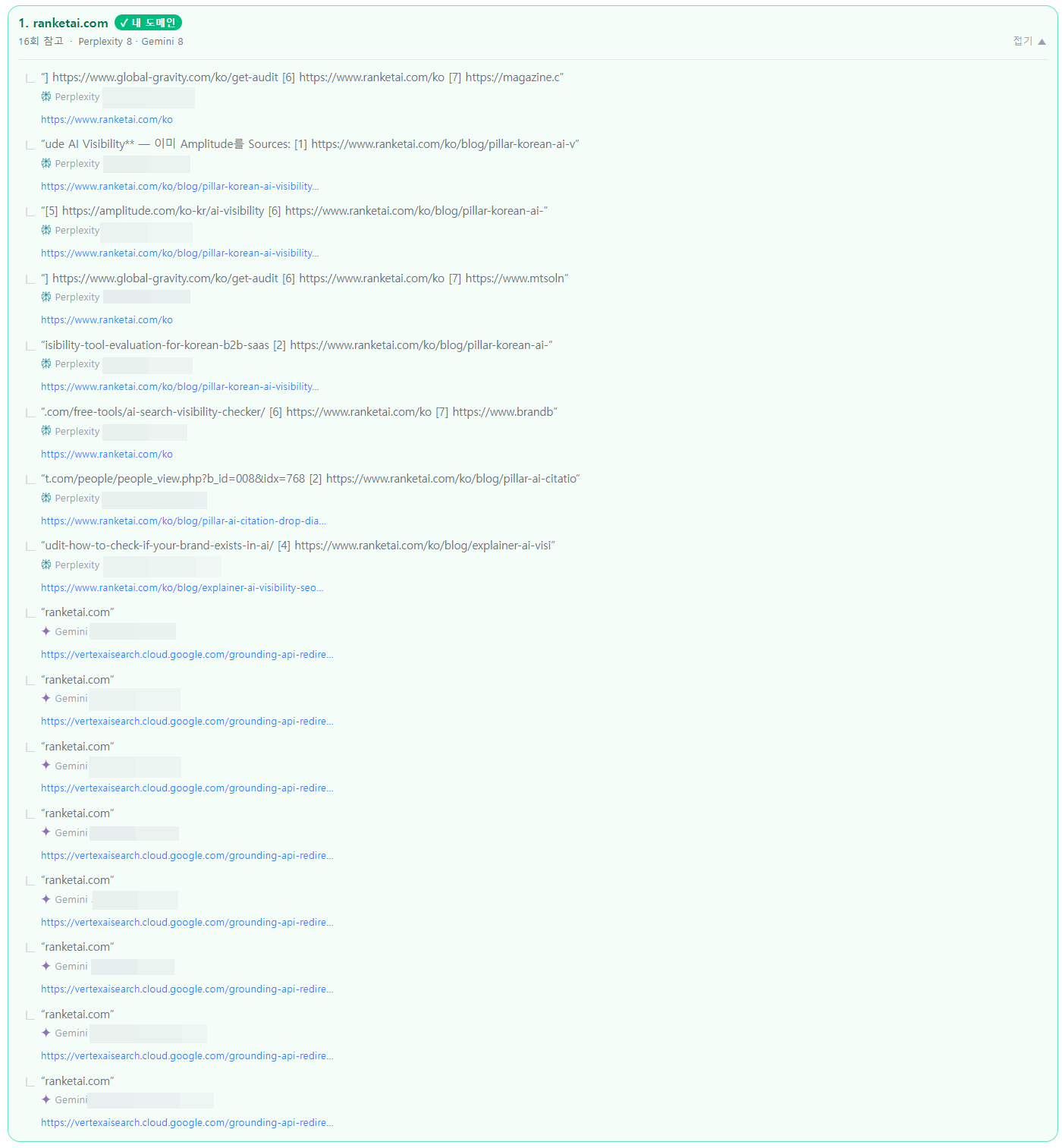
| 2026-06-07 | B | 16건 | 측정 조건 v2 첫 측정 — B 진입. Perplexity 8건 + Gemini 8건 (Gemini 인용 신규). ChatGPT는 웹 검색 조건에서도 브랜드 미언급 |
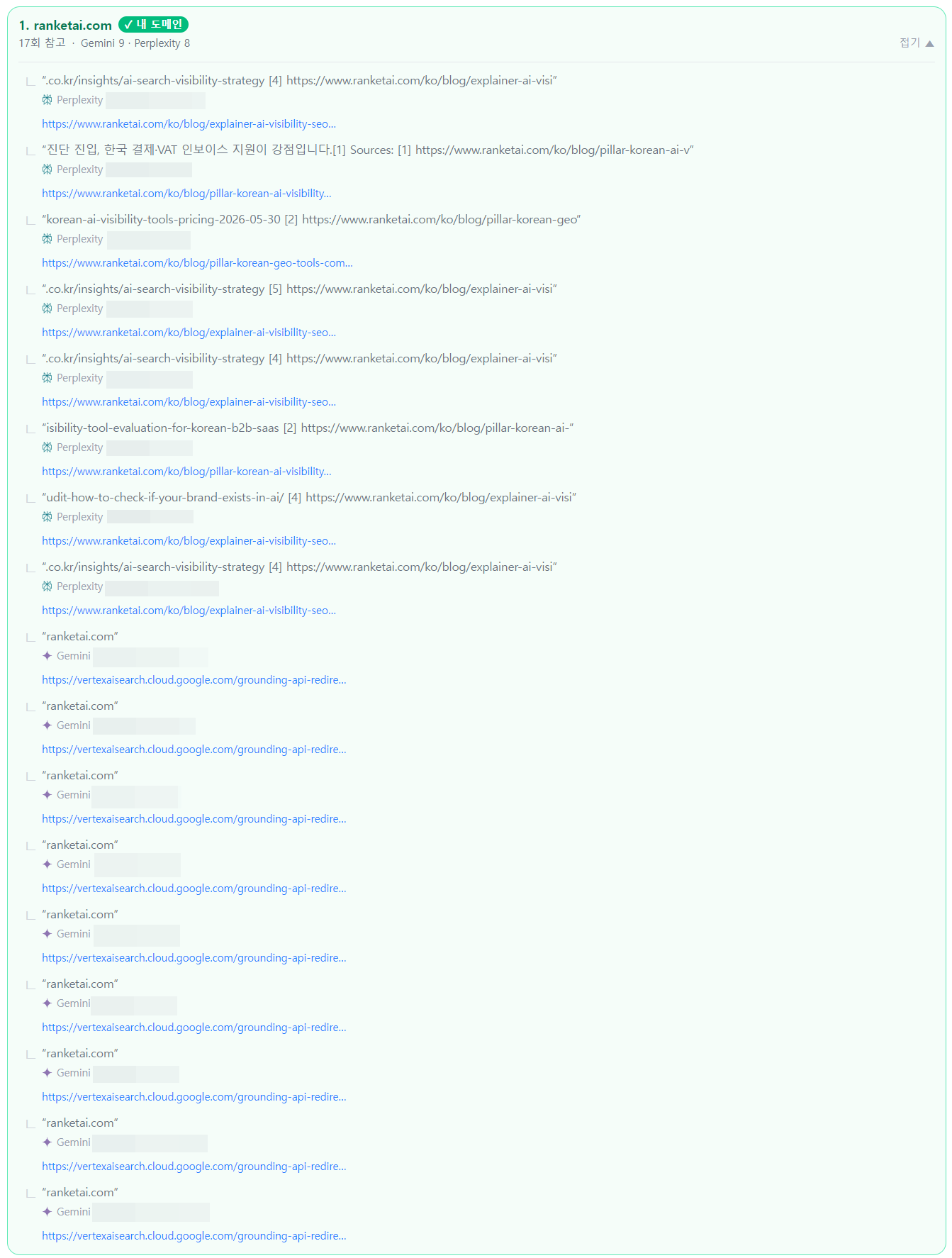
| 2026-06-13 | B | 17건 | B 유지 (2회 연속) — Perplexity 8건 + Gemini 9건. 인용 자산이 용어사전 중심에서 블로그 pillar·해설 글로 확대 |
※ 2026-05-25와 2026-06-07 사이에 측정 조건이 v1 → v2로 변경되었습니다(위 교정 섹션 참조). 5월과 6월 등급을 같은 자로 직접 비교하지 마세요.
C → B 사이에 적용한 활동
5.25(C) 측정 이후 6월 측정 전까지 적용한 활동입니다. 관찰된 상승과의 인과는 보장하지 않습니다 — 측정 조건 교정 효과와 섞여 있습니다.
브랜드 엔티티 구조화
- • 브랜드 정체성·카테고리·기능 키워드 3레이어 정의 — 스키마 entity·페이지 메타·JSON-LD에 일관 적용
- • 블로그·용어사전·use-case 40개 파일에 동일 엔티티 표현 일괄 동기화
콘텐츠 발행 + 외부 표면 직접 등재
- • 비교·가격·진단 가이드 중심 pillar 콘텐츠 5편 발행 (출처·통계 인용 형식)
- • Crunchbase·GPT Store 직접 등재 — 셀프서브 등재이며 언론 보도(earned media)가 아님
인용된 자사 페이지
최신 측정(2026-06-13) 기준 AI 답변에서 인용된 자사 페이지 목록입니다.
| 페이지 | 인용 응답 수 |
|---|---|
| 내 콘텐츠가 AI 검색에 안 뜨는 이유: AI 가시성 진단부터 SEO·AEO·GEO·AAO 전략까지/ko/blog/explainer-ai-visibility-seo-geo-aao-2026-03-14 | 5건 |
| 한국 AI 가시성 진단 도구 가격 비교 — 무료부터 엔터프라이즈까지 (2026)/ko/blog/pillar-korean-ai-visibility-tools-pricing-2026-05-30 | 2건 |
| 한국 시장 GEO 도구 비교 가이드 — 5 카테고리로 정리한 AI 검색 가시성 진단 도구 (2026)/ko/blog/pillar-korean-geo-tools-comparison-2026-05-30 | 1건 |
본 표는 2026-06-13 측정의 Perplexity 인용 8건(페이지 단위 식별 가능)만 집계. Gemini 인용 9건은 grounding 리다이렉트로 개별 페이지 식별이 제한되어 도메인 단위로만 확인 — 표에서 제외.
강점과 남은 갭
- • 강점 — 브랜드·카테고리 중심 질의: Perplexity·Gemini 답변에서 자사 페이지가 안정적으로 인용됩니다 (인용 도메인 1위).
- • 갭 — ChatGPT: 웹 검색 조건에서도 브랜드 미언급. 파라메트릭 지식과 외부 권위 인용 부재가 원인으로 추정됩니다.
- • 다음 프런티어 = 외부 인용(earned citation) — 2026-05 호에서 'C→B 진입 조건'으로 제시했던 earned media 가설을 B → A 구간 레버로 정정해 승계합니다.
측정 방법론
본 측정은 다음 원칙을 따릅니다.
- • 측정 도구: RanketAI 자체 도구 (dogfooding)
- • 측정 LLM: 주요 LLMs (ChatGPT · Gemini · Perplexity) — v2: 웹 검색·grounding 활성
- • 프롬프트: 다양한 의도별 조합
- • 등급: 4단계 (A / B / C / D)
한계
- • 측정 대상 = 자사 1 도메인 — 카테고리 표본 확대는 2026-07 호 (당초 6월 예고에서 일정 조정)
- • 스냅샷 5회는 추세가 아닙니다 — LLM 답변은 같은 조건에서도 측정마다 변동합니다(6.7과 6.13 사이에도 신호 구성이 달라짐). 등급은 보수적으로 해석하세요.
- • 시계열에 측정 조건 v1·v2가 혼재합니다 — C→B 상승분에서 콘텐츠 효과와 측정 교정 효과는 분리 검증되지 않았습니다.
- • 감정 분석은 본 호에도 수치로 포함하지 않았습니다(측정 간 변동성) — 다회 측정 평균 도입을 검토 중입니다.
- • 본 보고서는 자가 측정(self-reported)입니다 — 원시 집계는 data.json·data.md로 공개해 검증 가능성을 유지합니다.